Literary Detection With Your Home Computer
by Steven L. Richardson
 When he was about seven years old, my son Ben came up to me as I was reading the newspaper and said, "Dad, our computer is really smart!" "Why do you say that?" I asked. "Because I typed 'How many people are in the world?' and it said '* INCORRECT STATEMENT'." Probably the only answer that might have made the machine look stupid to Ben at that age would have been an "I don't know," which he and I now would recognize as a sign of true computer intelligence. I should probably mention that Ben asked his question to our Texas Instruments TI-99/4A, the only computer I know of that would answer a question in that way. IBM compatibles respond with a far less satisfying but equally cryptic "Syntax error".
When he was about seven years old, my son Ben came up to me as I was reading the newspaper and said, "Dad, our computer is really smart!" "Why do you say that?" I asked. "Because I typed 'How many people are in the world?' and it said '* INCORRECT STATEMENT'." Probably the only answer that might have made the machine look stupid to Ben at that age would have been an "I don't know," which he and I now would recognize as a sign of true computer intelligence. I should probably mention that Ben asked his question to our Texas Instruments TI-99/4A, the only computer I know of that would answer a question in that way. IBM compatibles respond with a far less satisfying but equally cryptic "Syntax error".
If there was some interface unit, with software to run it, that permitted the computer to somehow count all the people in the world (perhaps probing the planet from a satellite), Ben would have had a legitimate answer to his question. The computer can come up with the answer if it is given a real method to find it.
Now, I haven't yet tried this, but if you have a TI-99/4A, I'll suggest a question you might pose in TI BASIC: "Some have suggested that Shakespeare (who lived from 1564 to 1616) wrote parts of the 1611 King James Bible. Is this true?" I suspect your machine will respond with "* INCORRECT STATEMENT". This answer, which I believe is a correct one, may or may not fit with your opinion, but you need to ask yourself how the computer came up with its response. Somewhere in the dark recesses of its electronic circuitry, does your computer really know who wrote the Bible, or is it simply informing you that what you just typed doesn't make sense?
Since electronic computers became available they have been asked all sorts of questions by all sorts of people. It was probably ten years before I even thought I might someday be bringing a computer into my home that I heard frequent repetition of the phrase, "Garbage in, garbage out." The people who were saying these things were speaking of mainframe computers that cost hundreds of times more than the $139.95 that I paid for mine. The phrase is still true, and before we can accept anything a computer has told anyone else, we need to know where their computer got its information and how it processed it, as well as how it was interpreted.
For me, some of the more interesting questions concern the writing style of authors. I find that some writers are easy to read, but others are extremely boring. I find this to be true even if the subject they are writing about is of interest to me. I believe this observation may result from the way the writers construct their sentences, a thing we learn very early in life when we first begin to speak and to write.
Methods for studying writer's style were suggested as early as 1851, but the first major success story happened in 1964, when statisticians Frederick Mosteller and David Wallace studied the 85 Federalist essays, written by Colonial patriots John Jay, Alexander Hamilton, and James Madison. The essays have great historical significance because they urged and eventually persuaded Americans to ratify the U.S. Constitution, which created and empowered the Federal Government. Prior to the Mosteller-Wallace study, the identity of the author of twelve of these essays was undetermined. Based on a computer analysis of the style of authorship, it was shown with a high degree of certainty that James Madison was their author.
Much of the recent development of stylometric methods is due to the efforts of Andrew Q. Morton at the University of Edinburgh, Scotland. As a result of hundreds of text studies in several languages, he has discovered, among other things, that of the fourteen books in the New Testament supposed to have been written by the Apostle Paul, only Romans, Corinthians I and II, and Galatians were written by the same person, presumably St. Paul. The others must have been written by someone else. The computer study was unable to determine whether the remaining documents were perhaps ghostwritten under Paul's direction or forgeries, and how this information is to be interpreted is open to discussion.
The Book of Mormon is a religious book published by Joseph Smith in 1830, and is believed by Mormons to be the translation of a collection of writings by a succession of ancient American prophets, most of whom are said to have lived between the years 600 B.C. and 421 A.D. Mormons believe these writings were provided to Smith by an angel. In 1979 two Brigham Young University statisticians, Wayne Larsen and Alvin Rencher claimed that of the four Book of Mormon prophets who wrote multiple blocks of words large enough to be analyzed in detail multiple times, each has a style distinct from the others. This means each varies enough from the others in his use of what are called noncontextual keywords so that the author of a block of text could be consistently identified by the way his writings use these words. Twenty of the most common words of this kind are listed below:
Larsen and Rencher explained how they performed their analysis, but unfortunately, as many of you already know, statisticians really aren't very good at explaining statistics to non-statisticians.
Fortunately in 1982 a San Diego computer specialist, Robert L. Hamson, wrote a do-it-yourself book called The Signature of God where he claimed the same results, and using the King James Version of the Bible, he also disclosed his own discovery that the words of Jesus, which are shown in red in some Bibles, have a distinctly different style from that of the Gospel writers Matthew, Mark, Luke, and John, whose writings appear in black type, and who are quoting Jesus. He was able to consistently distinguish samples of text spoken by Jesus from its surrounding Gospel narrative using samples as small as 350 words studying just the three keywords "AND", "OF", and "TO". Of course, Hamson's computer merely confirmed things that he already was willing to believe.
Not to be outdone, an atheist, Ernest H. Taves, wrote a book which he titled Trouble Enough using computer studies to prove to his own satisfaction that the Book of Mormon contains only the writing style of Joseph Smith, confirming, like Hamson, what he already believes. Taves wrote a second book, This Is the Place, which contains an appendix that further expands upon his ideas. Though his motives, methods and data are open to and perhaps deserving of criticism, Taves applies the CuSum graph to stylometry, and effectively describes how to use it.
There are others who have tackled this problem and attempted to approach it from a purely scientific direction, most notably John Hilton and Ken Jenkins, scientists at the University of California, Berkeley. But some of their statistical methods are probably too exacting for beginners like us. But in case you're wondering, they begin with a sample of 4998 words and slice this into 17 blocks of 294 words each. Each of these blocks is analyzed 49 times rotating through the block in steps of 6 words to provide proper mixing for consistent results. After this--well, let's just say things start to get technical. I'm not so sure you and I need to carry our research out to these extremes unless we're trying to prove something to a high degree of statistical certainty to an audience that's inclined not to believe our evidence anyway.
The program accompanying this article is a very specialized word processor that utilizes nearly every stylometric method mentioned by Hamson and Taves, and you can use it to either determine which of the above researchers is right, or tackle the question of whether Shakespeare helped write the Bible. If you'd prefer to avoid religious controversy, you can use the program to study the styles of great writers such as Faulkner, Hemingway, Goethe, Cervantes, Poe, and (of course) yourself. You may wish to discover which of President Clinton's speechwriters wrote a particular speech, or you might want to investigate whether brothers and sisters raised in the same home share a similar writing style, or if a translated document carries the style of the original author or that of the translator, and if so, to what degree.
The program runs on any IBM compatible computer which has an 80 column screen display. It probably goes without saying that the more powerful the microprocessor, the faster the program will run. For the benefit of users of slower systems, some options display a countdown to give you an idea on how much longer the process will take. It has not been tested on every possible configuration, and there may be some variation between systems. Of course, it is up to you to satisfy yourself that the program is providing you with accurate results, perhaps by testing it on small batches of text with known characteristics. If you suspect there is a problem with the program, please let me know and I'll try to correct it.
To run the program all you need to do is type "stylo". You will be presented with the following menu:
Briefly stated, option 1 lets you create a file, typing in each word and pressing enter. The only keys you should use are A to Z, numbers, apostrophes, and periods. You can also use an asterisk to represent words you can't decipher, such as when you are reading handwriting, or when the author leads into a quote of another author (whose writings of course you should not be including in this file). If you want to stop entering text, type "XX" and enter. The program has been dimensioned to allow you to input as many as 5020 words. Should you attempt to type beyond that limit, the computer will automatically return to the menu, after trimming the file down to the end of the last sentence. An example file has been included on the disk that was created in this manner. It is called "spauldi1.xxx" and consists of the first 5006 words of Solomon Spaulding's Manuscript Found, which was written about 1812 and is believed by some to be the source document to the Book of Mormon. It can be loaded and examined using option 3. If the file is on a disk which you have in your "a" drive, the filename is "a:\spauldi1.xxx". The "a:" prefix is the drive name and may be something else, depending on how your system is configured. There are also more samples of Spaulding’s writing: "spauldi2.xxx" and "spauldi3.xxx".
If you wish to add words to an existing file, Option 2 allows you to pick up where you left off.
Option 3, Load File, requires some explanation: using it you can load a file that has been created using options 1 and/or 2. Actually, options 1 and 2 are not really the best way to input data; an easier method is to type the file using word processing software, such as WordPerfect. The file can then be saved in ASCII or Generic Word Processing format. Consult the manual that came with the word processing package for ideas on how this may be done (you may already have samples of your own writing that can be transformed in this manner). Then, by following the instructions at the top of the load screen, the file will be translated into the format used by this program. In doing this, the computer will follow the inputting rules explained above, ignoring all punctuation except apostrophes and periods. The entire file is also transformed character by character into uppercase letters.
It would be unfair not to inform you that there's an even easier method, since files may already exist on your hard drive, on a CD ROM device, or accessed from the internet through a modem. These files merely need to be loaded and transformed to the stylometry program's format, with little effort on your part. You can use the time you save to verify that the sample represents the writings of a single author. If you choose to import a file, the program will ask you for the source of the text. If the first line of the file you are importing contains a description of its source, you can press the enter key at the prompt “Source:”, and that description will be attached to your file. It can be further refined later to better identify the author. An example file is provided on the disk for you to experiment with. It can be loaded and transformed using the filename "#a:\alma39.txt"; the "#" prefix is an instruction to remove numeric characters, such as verse numbers. If there is a possibility that dates or other numbers may be included in the text, it becomes important that they not be removed. A sample of Solomon Spaulding’s writing can be loaded using "=a:\spauldin.txt" (and was used to create "spauldi2.xxx" and "spauldi3.xxx"). It was created in MicroSoft Word, and saved using the “Save As” command, saving as text with line breaks. After a file that has been created in this way has been loaded, it should be resaved to disk with another name, such as "alma39.xxx". The load screen also provides a method by which you can merge two files together. More will be said about this when we discuss option 8.
Sometimes the program will crash while trying to import a text sample. If that happens, and if you were loading the text with the filename preceded by "=" or "#", the screen will also indicate how far you got before the crash. Load the file into a word processor and reduce the size of the file to the end of the nearest sentence and try again. If it crashes again, remove another sentence.
Should you wish to review the file, it may be done using options 4 or 5. Of these, the first lets you read each sentence separated by blank lines. This way you can read what you have written or loaded and easily find problems in the text, such as words left out or misspelled. You can also find sentences that should be edited. The second method, option 5, lists each word preceded by its word number. If you find the list sweeping past too fast, pressing any key will pause the process; pressing any key again will restart it. When you have seen enough, press "Q" to return to the menu. This last instruction also applies to many of the functions described below.
Option 6 gives you limited editing abilities. "S" shows a word you select by its number and several words preceding and following it. "I" inserts a blank position to which a word can be added in a following step; "D" deletes a single word. "E" allows you to edit a word.
Option 7 lets you save to disk a file that you have created or loaded. Files are saved in ASCII format.
Now let's examine option 8. By its name, homogeneity, it might seem impossibly technical. But if you keep in mind that homogenized milk has been processed so that the cream no longer has the ability to separate, what we are testing for is how similar the file is to itself. The file is sliced up into samples, each initially consisting of 250 words (the size of the samples can be easily modified by holding down "Q" and entering the size you have chosen). A good way to compare the style of two authors is to use option 5 to list the words of the first author down to the end of a sentence at about word number 2500. Press "." at which the computer will ask where you want the period to go. Using option 3, a second file can now be added which will start at the ".." (which the program first transforms back to ".") and extend to word number 5020 or less, replacing the second half of the first author's writings with those of the second author. If the two authors exhibit different characteristics in their use of Morton's 20 keywords, or other keywords you may substitute in their place, it will make itself apparent on the graph on your screen in a way that will be obvious if you know how to interpret it. No author will consistently use the words "AND" or "THE" the same number of times for each hundred words he or she writes. The same is true for a thousand words, and even ten thousand. But the larger the sample the greater the possibility that the variations in the counts between blocks of text from a single author will decrease. Two documents written by the same undisputed author should be homogeneous, even when written at different times of the author's life. If the authors of two merged files are different in their use of the words "OF" or "TO", for example, there will be a dramatic change in that graph beginning at the point where the second file was merged to the first. This shouldn't be expected to happen with every word, but you should make a note of words for which it does happen when comparing two different authors. When testing the homogeneity of a sample of text from a single author, a style change noted at the same place for several keywords may mean that another writer contributed. The program has been instructed to provide you with the average of all the samples, called "Mean" (also projected out to counts per thousand), and the Standard Deviation, called "SDev". The Standard Deviation gives you an idea of how much a number can be plus or minus to the Mean before it can be considered abnormal. Those values that are abnormal are highlighted: highs in one text color, lows in another. These are also accompanied by a symbol: "^" for high, "~" for low. The smaller the number of words in each sample the more of these there will be, but if the writing sample is from a single author both colors of text would be evenly spread along the chart, more or less. If the highlighted numbers are on one end of the graph or the other, it may be an indication of a change of authors, something you can also intentionally introduce, as explained above. It may take you awhile to get a feel for how these concepts translate out on the graph, but hopefully you now know enough to get started.
The graphs presented below analyze the homogeneity for the word “AND” in the file “spauldi1.xxx” in 250, 500, and 1000 word units. You should notice a similarity between the graphs.
AND |
1-250 12 *|
251-500 13 +o
501-750 10 + o|
751-1000 19 ^ |o +
1001-1250 16 |o +
1251-1500 12 |o +
1501-1750 7 ~ +o
1751-2000 10 + o
2001-2250 19 ^ o +
2251-2500 17 ^ |o +
2501-2750 12 |o +
2751-3000 19 ^ |o +
3001-3250 15 |o +
3251-3500 14 |o +
3501-3750 10 |o +
3751-4000 5 ~ o +
4001-4250 17 ^ |o +
4251-4500 13 o +
4501-4750 9 o +
4751-5000 8 ~ *
Mean = 12.85 : 51 per 1000 |
SDev = 4.13
AND |
1-500 25 *|
501-1000 29 |o +
1001-1500 28 | o +
1501-2000 17 ~ + o|
2001-2500 36 ^ |o +
2501-3000 31 | o +
3001-3500 29 | o +
3501-4000 15 ~ |o +
4001-4500 30 |o +
4501-5000 17 ~ *
Mean = 25.70 : 51 per 1000 |
SDev = 7.04
AND |
1-1000 54 | *
1001-2000 45 + o |
2001-3000 67 ^ | o +
3001-4000 44 |o +
4001-5000 47 *
Mean = 51.40 : 51 per 1000 |
SDev = 9.56
To help you learn what to look for, you may wish to experiment with the following short BASIC program listed in Table 1. A copy of it is also on your disk, named "qsumdemo.bas". If you don't have BASIC, BASICA, GWBASIC, QBASIC or any other version, there is also an executable version called "qsumdemo.exe", which can be run by typing in "qsumdemo", but obviously can't be customized. When the program is run, each time you press enter you will see ten numbers displayed on the screen, they are then plotted on a graph showing the CuSum or Cumulative Sum, as developed by Morton, also the CuAve or Cumulative Average. These two numbers are equal at the beginning and end of the plot, but often take different routes as the plot progresses, and always end on zero. About the sixth time you press enter you should be seeing the type of graph that indicates different authors, first an ideal case, and then what you are more likely to encounter. Deviant values cause peaks on the chart. You are invited to modify the DATA statements and try the program using sets of 10 numbers of your own choice.
Further tests can be conducted on a single file by slicing it up into units, or blocks, then comparing them to each other by using the tests preceded on the menu by asterisks. Option 9 lets you determine which portion of the file you wish to test. The block should end when a sentence ends, so the locations of these are displayed on the screen. Regardless of the block size you select, each stylometric measurement, with the exception of alphabet (which is in percent), and sentence length (in words per sentence) will be projected to count per thousand. After a block size has been selected, the number of words in the block will be added to the lower right corner of the menu display to keep you informed. The results of the following tests can in most cases also be output to a printer by following the instructions at the bottom of the screen prior to the return to menu. As stated above, holding down "Q" through a cycle will give you the option to terminate most tests.
Option 10 plots a graph of word lengths, with a unit consisting of one character. This is based on the theory that some writers prefer to use longer words than others. The larger the sample, the more bell-shaped the curve described by the graph will be. You will also note you are given the opportunity to change block size in this and the following tests by simply typing in a range of word numbers. For example, entering "51-250" sets the block size at 200 words, with word 51 being the first and 250 being the last. The smaller the block you are testing, the less symmetrical or “bell shaped” the graph will appear to be.
Option 11 plots a graph comparing sentence lengths. The most ancient documents have no spaces or punctuation. Marks such as periods, question marks, exclamation points, commas, hyphens, colons, semicolons, and quotation marks are recent inventions, added to make the writing easier for us to understand. Before punctuation it appears many ancient writers developed a rhythm of some kind to let the reader know when the sentences ended, something like the way poets use lines of consistent length, or the way most songs contain a constant number of syllables per verse. Testing for sentence length has been successful with writings in ancient Greek and some other languages, but it appears that the introduction of punctuation has given modern writers more flexibility in how we express our ideas. The earliest manuscripts of the Bible and even the Book of Mormon had no punctuation. Maybe some thought should be given to the question of whether the people who later edited and punctuated these books knew what they were doing.
Option 12, Alphabet, simply counts the percentage of the sample used by each letter of the alphabet. Oftenrepeated keywords will have an effect based on the ratio of letters contained in them.
Option 13 deals with phrases that may reflect an author's word habits. The computer will search the document for two words of your choosing which occur either next to each other or separated by a fixed number of words. Any phrase that you suspect is repeated often by a writer can be located using this option. As an example, you might be looking for "AND * * AND". The search will present you with each time "AND" is separated by two other words inside the same sentence. Some advanced tests will require you to identify words, such as adjectives or verbs occurring in some position relative to a word, such as "TO". For example, for "AND adj" you simply enter "AND #" and identify the adjectives following "AND" as they march across your screen. Pressing the space bar after every ten counted helps you keep track; the computer will later ask you how many you counted and it will project your number to the count per thousand. Table 2 lists example phrases to search for. You can also use option 13 to search for phrases such as the Book of Mormon's "AND IT CAME TO PASS THAT" by searching for occurrences of six word phrases that contain an otherwise rare word pair "IT CAME" or "TO PASS" using your choice of either of the following search entries: "* IT CAME * * *" or "* * * TO PASS *". The two words don't have to be adjacent to each other; you can search for "* IT * TO * *" as well. The screen will display the search results, to help you determine if you are getting what you thought you were asking for.
Number 14, Strings, lets you search for occurrences of an alphabetic letter or combination of letters and, if you wish, replace them with another string. This may be useful for searching for words containing certain combinations of letters, such as "ION", "ING", or other style indicators. This option also allows you to painlessly replace abbreviations such as "DR.", "MRS.", and "ETC." with "DR", "MRS", and "ETC" removing false sentence endings from the file.
Option 15, Index Sentence, lets you search for occurrences of words in a certain position in the sentence. Some writers may frequently begin their sentences with "AND", or use "THE" as the second to the last word. This option permits you to test for these and other features. The method you are to follow in doing this is demonstrated each time you select this option. A prompt in the upper right corner of the screen reminds you that you can see a repeat of the demonstration by typing "?,0". Table 3 lists some tests you may want to try.
Although you should save a file as soon as it has been created, none of the above tests destroy the continuity of the file. The preceding statement isn't true of the next option, 16, so you should be sure you have saved the file before you try to Sort/Count. The program begins by sorting the entire word list into alphabetical order, the number of occurrences of each word is then counted and the count is tacked to the beginning of each string, which is then sorted again. The result is a listing of each word, preceded by the number of times per thousand it appears in the document. You are also informed how many words were introduced, which can provide insights into the magnitude of the author’s vocabulary. When the process of sorting and counting is done, the list is paraded past you on the screen. If you wish to cause the listing to pause, press any key. If you want to see it start listing from the beginning, press "Q". Other options will then be presented to you. Unlike the methods used by the other researchers, this program has been written to conserve paper. In printing the list it will format the report to five columns on usually two or three pages of paper (by doing this, some of the longer words may be truncated).
The final option, 17 Quit, reports how much memory is available, and if you choose, you can exit the program by following the instructions presented on the screen. To run without crashing, the program usually needs at least 1000 free bytes of string space after a file is loaded. This is where you can see how much memory you have.
Option 0 does not appear on the menu, but it loads a file named "setup.wpt" and allows you to configure the screen colors and output device to suit your needs. If you choose you may save the configuration or use the old one the next time you run the program. The output device can be a printer, such as "lpt1" or "com1", or a disk file name of your choosing, such as "c:\macbeth1.shk", which accumulates results each time you print to it during the session. When you are asked if you want to keep the setup, if you answer no, the setup is effective only until you exit the program. There is a backup of the original setup named "setup.bak".
There is a file called "keywords.wpt", which is a list of the keywords you wish the program to evaluate. If you become interested in the word "SO" as a keyword, you can add it to the list using 3 to load the file "keywords.wpt", then use option 2, Add to File to add "SO" to the list. Then using option 6, Edit, you should change record 0 from 20 to 21, which is now the number of keywords on the list. Having the ability to modify the list also allows you to perform studies on the use of noncontextual keywords by writers in other languages, such as German and French.
Results from the stylometric tests you will have performed can be recorded on a form of your own design, then transferred to a spreadsheet program such as MicroSoft Excel or Lotus 1-2-3, and analyzed using the methods described in Tables 2 and 3, and demonstrated on Table 4, plotted using graphing options, or evaluated by any other procedure you may think of. I suggest you study the works of writers such as Hamson and Taves for ideas, or curl up with a good statistics textbook.
And if you discover that Shakespeare really did write the Bible, before you organize a press conference, first carefully check your numbers to be certain you won't be embarrassed later. You probably need to sample several blocks each totaling 5000 or more words, if possible. The source for each text should be carefully identified. Once you have done this, consider the following: do all undisputed samples give the same results? Are there observations that you ignored (even subconsciously) that don't match to your conclusions? Are there freak events in the sample that may give misleading results? Was your analysis carefully and critically done? These are important questions that should be taken seriously. After all, we now live in a computer age. Anybody with a home computer can check your work.
Table 1Option 8: Homogeneity
CuSum-CuAve Demonstration Program in BASIC
10 REM CuSum-CuAve Demonstration
20 DATA 10,10,10,10,10,10,10,10,10,10,These are all the same number.
30 DATA 1,2,3,4,5,6,7,8,9,10,Ascending values.
40 DATA 10,9,8,7,6,5,4,3,2,1,Descending values.
50 DATA 1,10,2,9,3,8,4,7,5,6,Blend of alternating ascending and descending.
60 DATA 30,25,29,27,30,32,27,29,25,30,Typical data from one source.
70 DATA 20,15,19,17,20,22,17,19,15,20,Typical data from another source.
80 DATA 20,20,20,20,20,30,30,30,30,30,Two perfect sources combined.
90 DATA 30,30,30,30,30,20,20,20,20,20,This also is two perfect sources combined.
100 DATA 30,25,29,27,30,22,18,19,15,20,This is more what you'd typically expect.
110 DATA 20,16,19,17,22,30,27,29,25,30,Or else something like this.
120 DATA 0,0,0,0,0,0,0,0,0,0,You can change the program's DATA to experiment.
130 U=9 '=Screen background color ( 0=black 9=blue )
140 M=8 '=Vertical origin for plot and values list
150 L=71 '=Horizontal origin for values list
160 L$="Press Any Key":COLOR 15,U:CLS:LOCATE 3,3
170 COLOR 10:PRINT CHR$(250);:COLOR 7:PRINT " = CuSum"
180 COLOR 12:PRINT TAB(3);CHR$(249);:COLOR 7:PRINT " = CuAve"
190 COLOR 14:PRINT TAB(3);CHR$(15);:COLOR 7:PRINT " = ";
200 COLOR 10:PRINT CHR$(250);:COLOR 7:PRINT " + ";:COLOR 12:PRINT CHR$(249)
210 LOCATE 4,28:COLOR 15:PRINT "CuSum-CuAve Demonstration":COLOR 15
220 B=0:S=0:E=0:FOR I=1 TO 10:READ A(I):B=B+A(I):C(I)=B/I:NEXT I:D=B/10:READ Z$
230 REM A(I)=count C(I)=running average D=final average F=CuAve E=CuSum
240 REM Print Values on Screen
250 COLOR 7:FOR I=1 TO 10:LOCATE I+M,L:PRINT USING "###";A(I):NEXT I
260 REM Print Axis on Screen
270 COLOR 7:FOR I=0 TO 11:LOCATE I+M,40:PRINT CHR$(179):NEXT I
280 REM Plot CuAve Graph
290 COLOR 12:FOR I=1 TO 10:F=C(I)-D:X=40+F:IF X<1 THEN X=1
300 IF X>80 THEN X=80
310 Y=I+M:G=SCREEN(Y,X):LOCATE Y,X:PRINT CHR$(249):IF G=32 OR G=179 THEN 330
320 LOCATE Y,X:COLOR 14:PRINT CHR(15):COLOR 12
330 NEXT I
340 REM Plot CuSum Graph
350 FOR I=1 TO 10:E=E+A(I)-D:X=40+E:IF X<1 THEN X=1
360 S=S+(A(I)-D)^2:COLOR 10:IF X>80 THEN X=80
370 Y=I+M:G=SCREEN(Y,X):LOCATE Y,X:PRINT CHR$(250):IF G=32 OR G=179 THEN 390
380 LOCATE Y,X:COLOR 14:PRINT CHR$(15):COLOR 15
390 NEXT I:SD=SQR(S/(10-1)):LOCATE 23,3:PRINT Z$;:COLOR 23:PRINT TAB(68);L$;:COLOR 7
400 LOCATE 20,3:PRINT USING "* Mean =###.#";D:PRINT USING " * SDev =###.#";SD
410 FOR I=1 TO 10:COLOR 7:LOCATE I+M,L:IF A(I)>(D-SD) AND A(I)<(D+SD) THEN 460
420 IF SD=0 THEN 460
430 IF A(I)<(D-SD) THEN 450
440 COLOR 13:GOTO 460
450 COLOR 11:GOTO 460
460 PRINT USING "###";A(I):NEXT I
470 K$=INKEY$:IF LEN(K$)=0 THEN 470
480 K=ASC(K$) AND 95:IF K=81 THEN 500
490 IF A(1)>0 THEN 160
500 LOCATE 23,68:COLOR 28:PRINT CHR$(7);" That's All! ";CHR$(7):COLOR 15:END
Table 2Option 13: Phrases
As suggested by Morton, the following is a list of word combinations that he has had good results with, and that you may also wish to test for using the phrases option, number 13. Words in capitals should be typed in as is, words in lower case describe the word form you are looking for (adjectives, verbs, etc.) counted manually using "#" to search for them. The symbol "*" on the list below represents a word position which may be occupied by any word.
The results from each of these tests should be divided by the wordcount listed in the second column. This kind of processing can easily be accomplished by entering the results and simple formulas into Microsoft Excel, Lotus 1-2-3, or a similar spreadsheet program, as is demonstrated on Table 4.
Table 3Option 15: Index Sentence
These are suggested keys to search for using option 15. The resulting numbers are recorded and divided by the number in the second column. Nearly all the cases listed below employ "ss", which should be interpreted to represent the number of sentences in the sample.
Table 4Example Spreadsheet
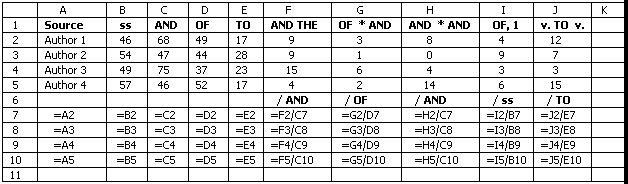
This is a simplified example of what you might do with a spreadsheet. Please note that the "*" in cell G1 is not a mathematical operator, but the "/" in cell G6 is, as explained in tables 2 and 3. Each spreadsheet software package has its own way of dealing with formulas, and some will allow you to name a column "THE", "OF", or "AND_*_AND". Many packages let you sort, insert columns and rows, rearrange data, transliterate, make graphs, and perform advanced statistical analyses with relative ease. To find out how to do these things, you obviously need to read the manual or tutorials that came with your spreadsheet software package.
To download a freeware copy of the Stylometry program, click on the token:
(The download is to be run from DOS on IBM compatible computers, and is 168 kilobytes in size.
It includes the example files that are discussed in the text above.)
To contact the author, Steve Richardson click here.
A version of this article written for the Texas Instruments 99/4A
home computer was published in 1994 in MICROpendium, V.11 No.1 pp. 8-16.
.